
Costruzione dei file e metadati
File standard
L'idea che sta alla base della costruzione del file standard è quella di sintetizzare le informazioni che in WHIP-Salute sono distribuite in molteplici archivi diversi svolgendo delle pseudo-interviste (pseudo-survey) su base individuale. Ovvero, per ogni individuo presente nel campione si definiscono delle domande cui viene data risposta interrogando gli archivi appropriati, e il risultato è registrato in un unico file.
Non vengono utilizzate le informazioni di tutti gli individui presenti, ma questi vengono ricampionati secondo uno schema di campionamento a rotazione simile a quello utilizzato nella Rilevazione sulle Forze di lavoro dell'Istat (RFL), in cui l'aspetto longitudinale è considerato secondo uno schema simile a quello utilizzato per l'indagine EU-Silc di Eurostat.
In particolare, nel primo anno si svolgono le pseudo-interviste a quattro gruppi distinti di individui (vedi figura). Per ogni anno successivo uno di questi gruppi viene escluso e non è più intervistato mentre ne entra uno nuovo: ogni gruppo viene così seguito per 4 anni.
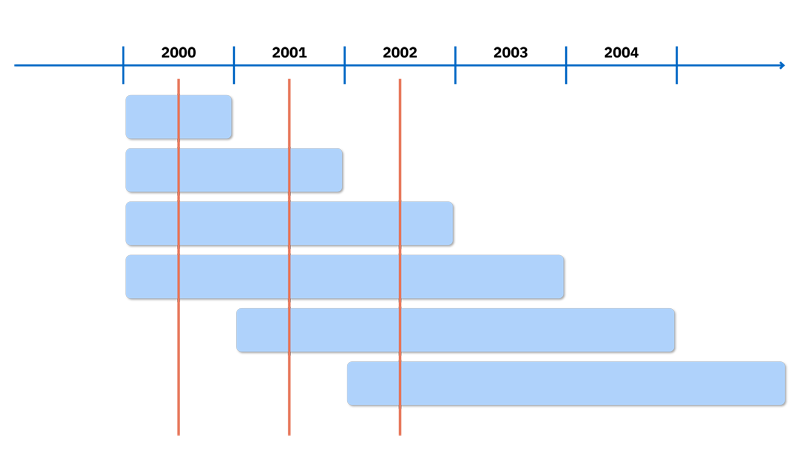
Le informazioni raccolte sono di quattro tipi:
Informazioni generali sull'intervista e sull'intervistato (DEM).
Informazioni retrospettive (RET): come in EU-Silc, all'arruolamento nella survey vengono raccolte informazioni riguardanti la carriera precedente della persona (anno di inizio lavoro, attività prevalente...).
Informazioni riferite all'anno (ANN): come in EU-Silc, vengono raccolte informazioni riassuntive che riguardano le attività tracciabili negli archivi INPS riferite all'anno in oggetto. In questa sezione vengono inoltre raccolte informazioni di salute (infortuni occupazionali e ricoveri ospedalieri) sempre relative all'anno in oggetto.
Informazioni riferite a un mese di riferimento (RIF): come nella RFL, vengono raccolte informazioni dettagliate sullo stato occupazionale e le sue caratteristiche in un dato momento dell'anno. Per la RFL le informazioni riguardano una determinata settimana nell'anno (detta settimana di riferimento); data la minor granularità delle informazioni presenti negli archivi le informazioni raccolte per produrre il file standard riguardano invece un dato mese di riferimento. In questa sezione vengono inoltre raccolte informazioni più dettagliate sugli infortuni occupazionali avvenuti nel mese di riferimento.
Informazioni generali sull'intervista e sull'intervistato (DEM).
Informazioni retrospettive (RET): come in EU-Silc, all'arruolamento nella survey vengono raccolte informazioni riguardanti la carriera precedente della persona (anno di inizio lavoro, attività prevalente...).
Informazioni riferite all'anno (ANN): come in EU-Silc, vengono raccolte informazioni riassuntive che riguardano le attività tracciabili negli archivi INPS riferite all'anno in oggetto. In questa sezione vengono inoltre raccolte informazioni di salute (infortuni occupazionali e ricoveri ospedalieri) sempre relative all'anno in oggetto.
Informazioni riferite a un mese di riferimento (RIF): come nella RFL, vengono raccolte informazioni dettagliate sullo stato occupazionale e le sue caratteristiche in un dato momento dell'anno. Per la RFL le informazioni riguardano una determinata settimana nell'anno (detta settimana di riferimento); data la minor granularità delle informazioni presenti negli archivi le informazioni raccolte per produrre il file standard riguardano invece un dato mese di riferimento. In questa sezione vengono inoltre raccolte informazioni più dettagliate sugli infortuni occupazionali avvenuti nel mese di riferimento.
In questo modo la dimensione longitudinale è garantita da quattro anni con un livello di dettaglio elevato delle informazioni, cui si aggiunge una informazione più sintetica relativa all'inizio carriera e ai 10 anni precedenti la prima intervista.
Nel file standard creato per la diffusione ovviamente non è presente alcun identificativo diretto né degli individui né delle imprese, ma come sempre va considerata la possibilità che, attraverso altre informazioni o l'incrocio di altre informazioni pubblicate, sia possibile un'identificazione indiretta delle persone.
Per avere un'idea del livello di identificabilità dei dati sono state calcolate delle misure di rischio dette livelli di k-anonimity o k-anonimità. Tali misure di rischio identificano una banca dati come protetta se il numero di individui che ha la medesima combinazione di modalità delle variabili chiave è maggiore o uguale a una soglia predefinita k, normalmente 2 o 3. Più in particolare, la grandezza che si vuole monitorare è il numero di volte in cui vi è una violazione della k-anonimità, intendendo per violazione il fatto che un individuo condivida lo stesso valore per tutte le variabili chiave considerate con un numero di altri individui inferiore a k. Nel caso della 2- anonimity più in particolare si parla di unici campionari: vi è un solo individuo con quella data combinazione di valori.
Bisogna però considerare che, nel caso di archivi campionari gli indicatori di k-anonimità sono specifici non della popolazione ma del campione stesso: ad esempio, non è detto che un unico campionario sia anche un unico di popolazione. Questo vuol dire che per valutare una banca dati come protetta occorre valutare statisticamente qual è la probabilità che un unico campionario sia anche un unico di popolazione. Queste misure sono state minimizzate intervenendo con tecniche standard di anonimizzazione (ad esempio l'aggregazione di modalità), per rendere il livello di anonimità paragonabile a quello misurato sui file per ricerca presi come riferimento, RFL e EU-Silc.
Per scaricare il documento integrale della pseudo-intervista: Intervista - File standard